
 个人中心
个人中心 我的认证
我的认证 我的课程
我的课程
对象的序列化与反序列化
操作在java.io中提供有两个处理类
第一:ObjectOutputStream extends OutputStream 继承自(OutputStream)是一个字节流的子类。
第二:ObjectInputStream
同样继承自InputStream
序列化后得到的是二进制文件
对象的序列化与反序列化
操作在java.io中提供有两个处理类
第一:ObjectOutputStream extends OutputStream 继承自(OutputStream)是一个字节流的子类。
第二:ObjectInputStream
同样继承自InputStream
序列化后得到的是二进制文件
打印流解决的是OutputStream的缺陷,BufferedReader解决的是InputStream的缺陷,
Scanner在Java.util.包中,解决的是BufferedReader类
Scannner 主要解决扫描流的程序类,利用这个类可以方便的处理各种数据类型,也可以直接结合正则表达式来进行各项处理。主要关注:
1 判断是否有指定类型的数据hasNextLong
2 取得置顶类型的数据 public nextLong
3定义分隔符public Scanner useDelimiter(String pattern)【调用了正则】
构造方法 public Scanner(InputStream input)
Scanner scanner =new Scanner(System.in);
因为System.in 是InputStream 的 一个方法。比BUfferedReader 要简单一点。
hasNext() 不能判断为空。减少转型处理。
如果需要一个int 数据,则
if(scanner.hasNextInt()){
int age=scan.nextInt();} 表示,只有数据为Int的时候,才能给age进行赋值。极其便捷。可以用正则表达式进行判断。
Scanner 本身可以接收一个InputStreem类的对线,同样也可以接受文件输入流。
Scanner 完美替代BufferedReader,更好地实现了InputStream的操作
总结,除了二进制文件的拷贝操作,程序信息输出用打印流,输入则采用Scanner 流
通过BufferedReader类,输入缓冲输入流 而且是一个字符流的输入流。
BufferedInputStream 与BufferedReader一起来处理中文。
在BufferedReader 类中,有一个readLine()方法,可以用于读取一行数据。也就是以回车为换行符来读取一行数据。
public BufferedReader(Reader in)
使用的时候有一个问题,实现键盘输入,由于接收的数据类型为String,也就可以采用正则判断。利用String类的各种操作进行数据处理,变为各种常用的数据类型。
打印流
字节打印流PrintStream、字符打印流PrintWriter
PrinteStream类:(outputStream为参数)
大引流的设计 是装饰性的设计,核心依然是某一个类、
使用打印流
Java IO 编程 打印流
OutputString的输出时候,有两个缺点,其一:数据必须变为字节数组
其二:只支持String——如果要输出的是int double等类型就不方便了
打印流逃不开OutputString
自己编写一个类,支持更多的输出支持。
PrintSream PrintWriter
希望利用程序来实现文件的拷贝。
通过初始化参数接收源文件和目标文件的路径,完成拷贝方法。
实现:
实现数据拷贝需要通过流 字节流比较合适。
在进行拷贝的过程中 在程序中开辟一个数组,这个数组的长度为文件的长度,将所有的数据一次性读取到该数组中,随后将该数组进行输出。
应该采用边读、边写的方式来完成。
转换流:字节流和字符流可以相互转换
OutputStreamWriter:将字节输出流转换成字符输出流
InputStreamReader 将字节流转换成字符输入流
转换的意义
OutputStraemWriter 是 writer 的子类
INputStreamReader 是Reader 的子类
将字节的输出流转换成字符的输出流
将字节的输入流转换成字符的输入流
writer 的输出要比OutputStream 的输出要方便,可以直接输出字节。
同理,InputSream读取的是字节,不方便中文处理。
主要是为了分析FileOutSream
FileWriter 是OutSreamWriter的子类
FileReader 是InSreamWriter的子类
字符流处理的时候的确经过了转换才得来的。读取的都是字节,而后再经过内存的处理才会变换成字符。也即字符是经过字节流的转换才得来的。
主要的区别是不大的,但是在处理中文的时候才会使用到字符流。因为所有的字符都需要用内存缓冲再进行处理
当进行数据传输的时候,要分为两个端,一个发送,一个接收。
网上传输的都是字节。也就是01码
读、写都需要缓存的处理
字节输出
内容在缓冲中。
如果在使用字符流操作时,内容就有可能在缓存之中。所以必须强制刷新才能得到完整的缓冲。{关闭操作后才能输出close()}
写上out.flush()就会强制输出。
总之,是先放置在缓存中。不论是文件、文字、图片,都可以使用字节流,只有在处理中文的时候,才会使用字符流。
类的定义结构
字节数出流OUtPutStraem
有两个接口
outPutStream{abstract}
closeable《Interface》 close
Flushable《Interface 》 flush
autocloseable
可以发现OutPutStream类中实现了Closeable Flushable 两个接口,跑出IOexception
接口比问题出现的晚。
内部含有close 和flush方法。
write 方法时关键
public void write(byte[] b) 将给定的字节数组内容全部输出
public void write(byte[] b,int offset int length) 将部分字节输出
public abstruct void write(int b)throws Exception 抽象方法,输出单个字节
outputsream 是一个抽象类,如果想要父类实例化,那么就要使用子类实例化。此处所关注的只关注子类的构造方法,可以使用FileOutput Stream 的类中的方法。
接收File类
public FileOutputStream(File file,Boolean append )throws FileNotfoudException 追加,append 为true 时,表示追加
关于输出的异常抛出
output.write(str.getBytes(),1,1) 最常用的输出语句
实现文件内容的输出
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStream;
public class TestDemo{
public static void main(String[] args) throws Exception{
File file=new File("e:"+File.separator+"hello.txt");
if(!file.getParentFile().exists()) {
file.getParentFile().mkdirs();
}
//outputStream 是一个抽象类, 需要子类进行实例化,一位置只能进行文件处理
OutputStream output=new FileOutputStream(file) ;
//进行文件的输出操作
String str="helloworld";//要求输出的内容
output.write(3);//需要把str 的内容转换成字节的形式
output.close();//关闭输出
}
}
首先是正则标记
在java.util.regex.pattern 中有定义
有一些标记,而且不断扩充。
第一组:
【单个】描述某一个字符
x:表示由x来组成
\\\\→\\ →(在正则表达式里)\
\t 是制表符
\n 为换行
【单个】 描述一个范围
[abc]表示表示为字母a/b/c 中的任意一个,是一个范围
[^abc] 表示不是在abc范围内
[0-9]相当于字符的0~9,由数字组成
[a-zA-Z] 不区分大小写的字母
. 表示任意的字符 而且.和\\ . 是不同
\d是表示0~9数字
\D 表示任意的非数字
\s 是以为空格, 或者是\t \n
\s 是非空格
\w 等价于字母、数字 下划线所组成
\W为非字母数字下划线
在javascript中要使用
比如^ 表示正则的开始,$ 表示正则的结束
数量表达式
重复出现N次
正则? 为一次或者零次。
正则来进行字符串的验证
一些简单的验证需要java大量的代码。
引入java.util.regex
06:39
Class.getFields() 并非取得父类属性,应该描述为取得该类拥有的所有public 属性,包括本类以及所有父类。
Class.getMethods() 同理。
资源文件下载地址:http://propedit.sourceforge.jp/eclipse/updates/
资源文件名称:包.文件前缀,没有文件后缀
取得当前日期时间数的方法:
public static long currentTimeMillis()
此方法可取得某方法的使用时间,毫秒为单位
long end=system。currentTimeMillis()
面试题:
final是一个关键字,用于定义不能够被继承的方法,父类,以及常量
finally:是一个异常处理的统一
首先说到线程就要提一下进程:
一个程序的执行周期就是一个进程 。
不管有多少块CPU,最后都是一块空间进行程序 处理
在单cpu的情况下 多个程序同时执行时就需要对源进行轮番使用就
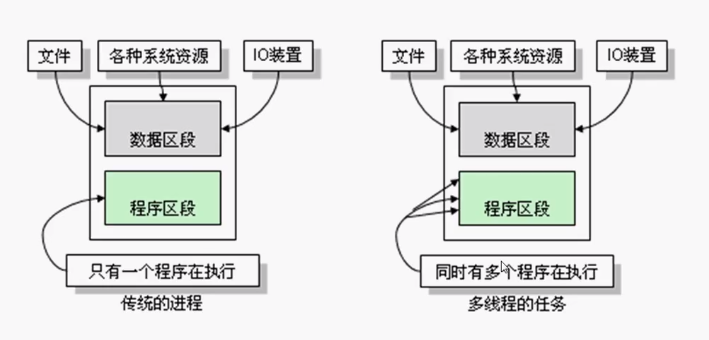
在传统进程中 在一个程序执行的时候所有的资源只为这一个程序服务
而在现阶段 还是只有一块资源而这一块资源就要被程序轮番占用
一块资源在同一时间段内可能会有多个进程交替执行,但是在某一时间点上只能有一个进程在执行。
多线程
线程是在进程的基础上进一步划分,也就是说线程是比进程更小得执行单位。
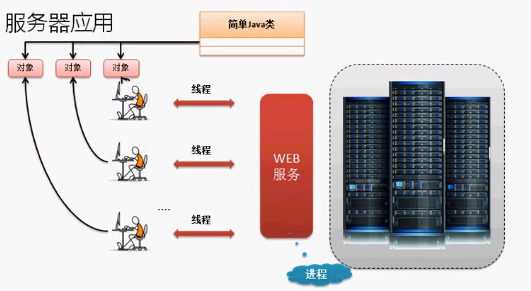
在服务器应用中 web服务就相当于一个进程,而不同用户访问这个进程就是一个线程,线程拥有自己的对象,而这些线程都是指向同一块堆内存。
并发就是访问的进程量爆高,最直白的问题就是服务器的内存不够用了,无法创建新的用户(线程)。
在开发之中,如果要使用ArrayList最好的做法就是设置处置初始化的大小,因为如果不设置好初始化长度,就会从空的对象数组开始,进行频繁动态的扩充,影响性能。
从理论上讲contains和remove需要equals的支持,有时候需要重写简单Java类里面的equals方法
//只允许保存String类型数据 ArrayList arrayList = new ArrayList(); arrayList.add("Hello"); arrayList.add("Hello");//重复数据 arrayList.add("Wolrd"); System.out.println(arrayList);
允许重复
ArrayList子类:(90%优先项)
ArrayList是一个针对于List接口的数组操作实现。
List存在有一个get()方法,可以结合索引取出数据;
千万记住get()方法是Collection子接口List的,如果使用的不是Listj接口的子类,那么就无法使用get()方法。
思路:如果使用的不是List接口而是Collection,只能将Collection变为对象数组来操作然后利用get()方法将数据取出。(不到万不得已,尽量别这么玩,会造成ClassCastException安全隐患)。
集合:
List接口:
允许重复,有序
List接口的使用比率可以到达Collction接口使用比率的80%,在进行Collection集合处理的时
候优先考虑List集合接口
List接口中的方法:
两个扩充的方法:
public E get(int index) 通过索引找到List中的索引数据
public E set(int index, E element) 修改数据
List三个常用子类:
ArrayList(优先考虑),Vector,LinkedList
最终的操作还是应该以接口为主,所以所有的方法只参考接口的定义就够了
魔乐科技软件学院