
 个人中心
个人中心 我的认证
我的认证 我的课程
我的课程
以前在学校学的时候感觉好难,现在再看感觉没什么是学不会的,向量、矩阵就这几个概念,没难度
矩阵概念
矩阵就是映射
矩阵是对运动的描述
以前在学校学的时候感觉好难,现在再看感觉没什么是学不会的,向量、矩阵就这几个概念,没难度
矩阵概念
矩阵就是映射
矩阵是对运动的描述
导数(Derivative)、梯度
导数:微积分学中的基础概念,一个函数的在某一点的导数描述了函数在这一点附近的变化率
导数的本质是通过极限的概念对函数进行局部的线性逼近
当函数f的自变量在一点x0上产生一个增量h时,函数输出值的增量与自变量增量h的比值在h趋于0时的极限如果存在,即为f在x0处的导数,记作f'(x0)
可写作:
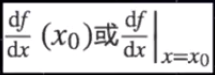
偏导数:一个多变量的函数的偏导数是它关于其中一个变量的导数,而保持其他变量恒定
曲面上的每一天都由无穷多条切线,描述这种函数的导数相当困难,偏导数即选择其中一条切线,并求出它的斜率。
几何意义上偏导数即为函数在坐标轴方向上的变化率
方向导数:函数的变化率与方向相关,即某一点在某一趋近方向上的导数值。对于多变量函数,自变量有多个,表示自变量的点在一个区域内变动,不仅可以移动距离,而且可以按任意方向来移动同一段距离。

几何意义上方向导数为函数在某店沿着其他特定方向上的变化率

因此,函数的变化不仅与移动的距离有关,而且与移动的方向有关。
梯度:函数在某一点处的方向导数在其梯度方向上达到最大值,即梯度的范数,沿梯度方向,函数值增加最快。

特殊的方向导数。
最优化方法及其应用
最优化方法:研究在给定约束或者无约束情况下如何寻求某些因素的量,以使某一(某些)指标达到最优的一些学科的总称。
大部分机器学习算法的本质都是建立优化模型,通过最优化方法对目标函数(货损失函数)进行优化,从而训练出做最好的模型。
常见最优化算法:
梯度下降法(Gradient Descent)
牛顿和拟牛顿法(Newton's method &Quasi-Newton Methods)
梯度下降法:
最早最简单,最常用。当目标函数拾一个凸函数时,梯度下降法 的解是全局解,但满足凸函数条件较为苛刻,一般情况下,不保证是全局最优解。
凸函数:数学函数的一类特征。凸函数就是一个定义在某个向量空间的凸子集C(区间)上的实值函数。
凸函数是一个定义在某个向量空间的凸子集C(区间)上的实值函数f,而且对于凸子集C中任意两个向量, f((x1+x2)/2)>=(f(x1)+f(x2))/2,则f(x)是定义在凸子集c中的凸函数
优化思想:用当前位置负梯度方向作为搜索方向,因为该方向为当前位置的最快下降方向,越接近目标值,步长越小,梯度越慢。
两种方法:基于基本梯度下降法发展处两种梯度下降方法,分别为批量梯度下降法和随机梯度下降法,以线性回归模型为例:
拟和函数:
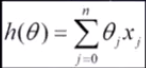
损失函数:

J(θ):损失函数
θ:参数,要求迭代求解的值
m:训练集的样本个数
n:特征个数
批量梯度下降法:
步骤:
(1)将J(θ)对θ求偏导,得到每个θ对应的梯度:
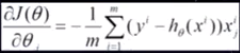
(2)最小化风险函数,按每个参数θ的梯度负方向,来更新每个θ:
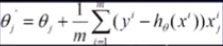
(3)每迭代一步都要用到训练集所有的数据,如果m很大,那么迭代速度回很慢
随机梯度下降法:
步骤:
(1)损失函数对应训练集中每个样本的粒度:

(2)每个样本的损失函数,对θ求偏导得到对应梯度,来更新θ:
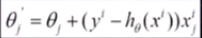
(3)随机梯度下降是通过每个样本来更新迭代一次,如果样本量很大,可能只用到 其中一部分,就将θ更新到最优解了。
虽然不是每次迭代得到的损失函数都向着全局最优方向,但大的整体方向是向全局最优解的,最终结果拾在全局最优解附近,适用于大规模训练样本情况。
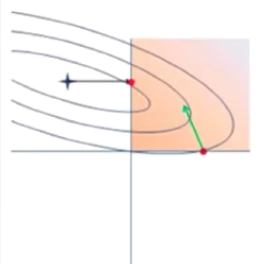
牛顿法:
在实数域和复数域上近似求解方程的方法。使用函数f(x)的泰勒级数的前几项来寻找f(x)=0的根,最大特点在于收敛速度很快。
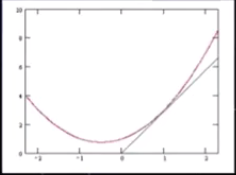
从几何上看,牛顿法是一个用二次曲面去拟合当前所处位置的局部曲面,而梯度下降法是用一个平面去拟合当前的局部曲面,通常二次曲面的拟合会比平面好,所以牛顿法选择的下降路径更符合真实的最优下降路径。
红色:牛顿法 ;绿色:梯度下降法

拟牛顿法:
求解非线性优化问题最有效的方法之一
本质思想拾改善牛顿法每次需要求解复杂的Hessian矩阵的 逆矩阵缺陷,使用正定矩阵来近似Hessian矩阵的逆,从而简化了运算的复杂度

Bk是一个对称正定矩阵,取二次模型的最优解作为搜索方向,并且得到新的迭代点:

常用的拟牛顿法有DFP算法和BFGS/L-BFGS算法
OWLQN(面向L-BFGS算法)在CTR(点击率)预测中的应用
逻辑回归模型:计算广告中的明星模型
在线行回归基础上,套用了一个逻辑函数


单个样本的后验概率:
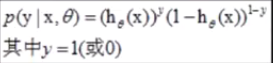
逻辑回归模型的极大似然函数:
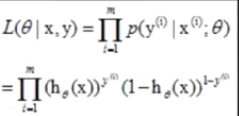
log似然: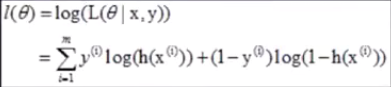
似然最大化转化为最小化:
l(x)即logg似然函数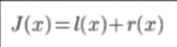
r(x)为正则:Regulation term,用来对模型空间进行限制,从而得到一个更“简单”的模型
常用正则:
L1-norm:模型函数服从Laplace分布:

L2-norm:模型函数服从Gaussian分布:
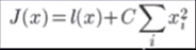
L1-norm和L2-norm之间的一个最大区别在于前者可以产生稀疏解,使它同时具有了特征选择的能力,此外,稀疏的特征权更具有解释意义。
次导数及次微分:出现不可导点时求微分

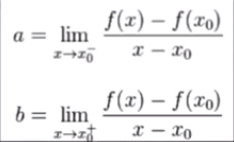
在点x0的次导数的集合是一个非空闭区间[a,b],其中a和b拾单侧极限
a,b一定存在,且满足a≤b,所有次导数的集合[a,b]称为函数f在x0的次微分
求一维搜索的可行方向时用虚梯度来代替L-BFGS中的梯度
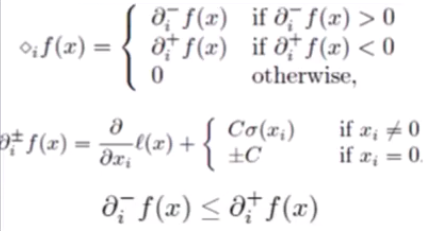
对于非光滑函数,虚梯度的选择有三种情况:
(1)αi-f(x)>0
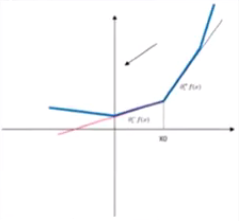
(2)αi+f(x)<0

(3)Otherwise

限制:
一维搜索要求不跨越象限,要求更新前权重与更新后权重同方向

梯
阿里云全球培训中心